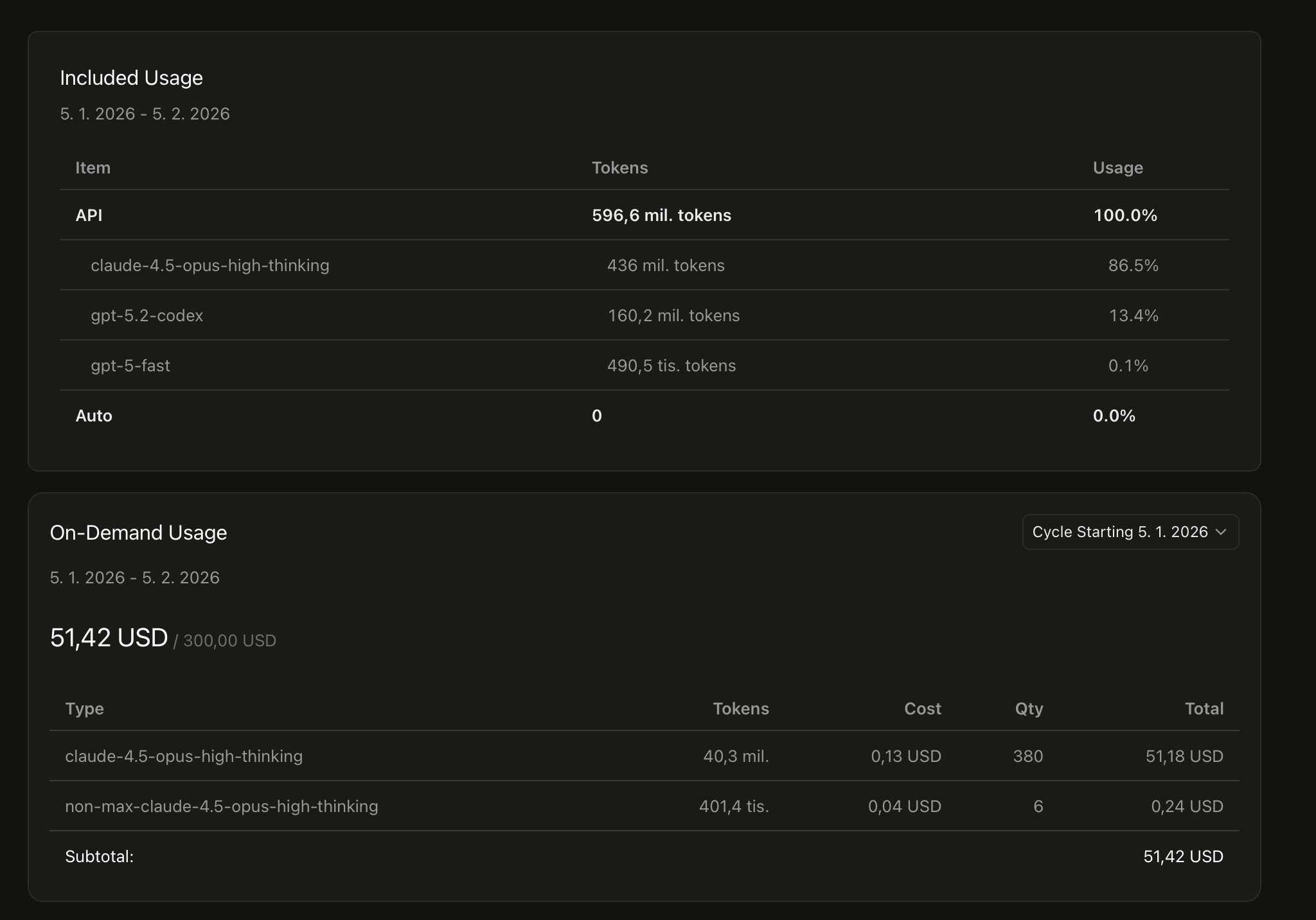
The Cursor dashboard said 596 million tokens. One month. Half a billion tokens of talking and building with machines.
I’m on the Ultra plan—$200/month for what’s marketed as $400 worth of API usage. The math sounds good on paper. In practice, something feels off.
The responses are slower than when I was paying per-token through the API directly. Not dramatically—but noticeably. That half-second lag that breaks your flow. The thinking indicator that spins just a bit too long.
I’ve wondered if there’s throttling happening beneath the surface. Some invisible queue where flat-rate customers wait while pay-per-request users get priority. I can’t prove it. But 86% of my usage is claude-4.5-opus-high-thinking, and at 2am when I’m deep in a problem, that extra latency adds up.
Complaining about AI being slightly slow is a strange luxury to have.